Construyendo un Chatbot simple desde cero en Python (usando NLTK)
Gartner estima que para 2020, los chatbots manejarán el 85 por ciento de las interacciones de servicio al cliente; Ya están manejando alrededor del 30 por ciento de las transacciones ahora.

Estoy segura de que has oído hablar de Duolingo : una popular aplicación de aprendizaje de idiomas, que ayuda en el proceso de aprendizaje de un nuevo idioma. Esta herramienta es bastante popular debido a sus sistemas innovadores a la hora de enseñar una nueva lengua. El concepto es simple: de cinco a diez minutos de capacitación interactiva al día es suficiente para aprender un idioma.
Sin embargo, a pesar de que Duolingo está permitiendo que las personas aprendan un nuevo idioma, a los practicantes les preocupa. Las personas sintieron que se estaban perdiendo el aprendizaje de valiosas habilidades de conversación ya que estaban aprendiendo por su cuenta. Las personas también estaban preocupadas por ser emparejadas con otros estudiantes de idiomas debido al miedo a la vergüenza. Esto estaba resultando ser un gran cuello de botella en los planes de Duolingo .
Así que su equipo resolvió este problema mediante la creación de un chatbot nativo dentro de su aplicación, para ayudar a los usuarios a aprender habilidades de conversación y practicar lo que aprendieron.
.
Dado que los bots están diseñados para ser conversadores y amigables, los estudiantes de Duolingo pueden practicar la conversación a cualquier hora del día, utilizando los personajes que elijan, hasta que se sientan lo suficientemente valientes como para practicar su nuevo idioma con otros speakers. Esto resolvió un pain point para el consumidor e hizo que el aprendizaje a través de la aplicación fuera mucho más divertido.
Entonces, ¿qué es un chatbot?
Un chatbot es una pieza de software con inteligencia artificial en un dispositivo (Siri, Alexa, Google Assistant, etc.), aplicación, sitio web u otras redes que intentan medir las necesidades de los consumidores y luego ayudarlos a realizar una tarea particular como una transacción comercial. Reservas de hoteles, envío de formularios, etc. Hoy en día, casi todas las empresas tienen un chatbot implementado para interactuar con los usuarios. Algunas de las formas en que las empresas están utilizando los chatbots son:
· Para entregar información de vuelo.
· Para conectar a los clientes y sus finanzas.
· Como soporte al cliente.
Las posibilidades son (casi) ilimitadas.
La historia de los chatbots se remonta a 1966, cuando Weizenbaum inventó un programa de computadora llamado ELIZA. Imitaba el lenguaje de un psicoterapeuta desde solo 200 líneas de código. Todavía puedes conversar con él aquí: Eliza.
¿Cómo funcionan los chatbots?
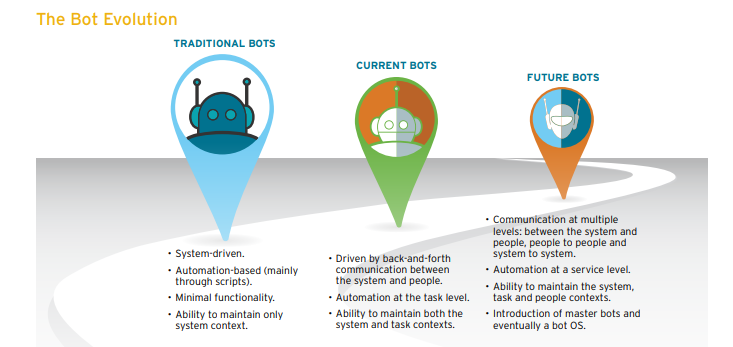
En términos generales, existen dos variantes de chatbots: basadas en reglas y autoaprendizaje.
1. En un enfoque basado en reglas, un bot responde preguntas basadas en algunas reglas que previamente han sido entrenadas. Las reglas definidas pueden ser muy simples o muy complejas. Los bots pueden manejar consultas simples pero fallan en administrar las complejas.
2. Los robots de autoaprendizaje son los que utilizan algunos enfoques basados en el aprendizaje automático y son definitivamente más eficientes que los robots basados en reglas. Estos bots pueden ser de otros dos tipos: basados en recuperación o generativos.
i) En los modelos basados en recuperación , un chatbot utiliza cierta heurística para seleccionar una respuesta de una biblioteca de respuestas predefinidas. El chatbot utiliza el mensaje y el contexto de conversación para seleccionar la mejor respuesta de una lista predefinida de mensajes a dar. El contexto puede incluir una posición actual en el árbol de diálogo, todos los mensajes anteriores en la conversación, variables guardadas previamente (por ejemplo, nombre de usuario). Las heurísticas para seleccionar una respuesta se pueden diseñar de muchas maneras diferentes, desde la lógica condicional en el que se basan las reglas o los clasificadores de aprendizaje automático.
ii) Los bots generativos pueden generar las respuestas y no siempre responden con una de las respuestas de un conjunto de respuestas. Esto los hace más inteligentes a medida que toman palabra por palabra de la consulta y generan las respuestas.
Construyendo el bot
Requisitos previos
Se asume un conocimiento práctico de scikit biblioteca y NLTK. Sin embargo, si eres nuevo en la PNL, aún puedes leer el artículo y luego volver a consultar los recursos.
NLP
El campo de estudio que se centra en las interacciones entre el lenguaje humano y las computadoras se denomina Procesamiento del lenguaje natural, o PNL, para abreviar. Se encuentra en la intersección de la informática, la inteligencia artificial y la lingüística computacional [Wikipedia].
NLP es una forma en que las computadoras analizan, comprenden y derivan el significado del lenguaje humano de una manera inteligente y útil. Al utilizar el PNL, los desarrolladores pueden organizar y estructurar el conocimiento para realizar tareas como el resumen automático, la traducción, el reconocimiento de la entidad nombrada, la extracción de relaciones, el análisis de sentimientos, el reconocimiento de voz y la segmentación de temas.
NLTK: Una breve introducción
NLTK (Natural Language Toolkit) es una plataforma líder para crear programas Python para trabajar con datos en lenguaje humano. Proporciona interfaces fáciles de usar para más de 50 recursos corporales y léxicos , como WordNet, junto con un conjunto de bibliotecas de procesamiento de texto para clasificación, tokenización, derivación, etiquetado, análisis y razonamiento semántico, envoltorios para bibliotecas de PNL de potencia industrial.
NLTK ha sido llamada “una herramienta maravillosa para la enseñanza y el trabajo en lingüística computacional con Python” y “una biblioteca increíble para jugar con lenguaje natural”.
El procesamiento del lenguaje natural con Python proporciona una introducción práctica a la programación para el procesamiento del lenguaje. Recomiendo este libro a las personas que comienzan en PNL con Python.
Descargando e instalando NLTK
- Instalar NLTK: ejecutar
pip install nltk - Instalación de prueba: ejecutar y pythonluego escribir
import nltk
Para obtener instrucciones específicas de la plataforma, pues acudir a este enlace aquí .
Instalación de paquetes NLTK
Importar NLTK y ejecutar nltk.download().Esto abrirá el descargador de NLTK desde donde puedes elegir los corpus y modelos para descargar. También puedes descargar todos los paquetes a la vez.
Preprocesamiento de texto con NLTK
El problema principal con los datos de texto es que todo está en formato de texto (cadenas). Sin embargo, los algoritmos de aprendizaje automático necesitan algún tipo de vector de características numéricas para realizar la tarea. Entonces, antes de comenzar con cualquier proyecto de PNL, debemos preprocesarlo para que sea ideal para trabajar. El preprocesamiento de texto básico incluye:
- Convertir todo el texto en mayúsculas o minúsculas , para que el algoritmo no trate las mismas palabras en diferentes casos como diferentes.
- Tokenización : Tokenización es solo el término usado para describir el proceso de conversión de las cadenas de texto normales en una lista de tokens, es decir, las palabras que realmente queremos. El tokenizador de oraciones se puede usar para encontrar la lista de oraciones y el tokenizador de palabras se puede usar para encontrar la lista de palabras en cadenas.
El paquete de datos NLTK incluye un tokenizer Punkt previamente entrenado para el inglés.
- Eliminar ruido, es decir, todo lo que no esté en un número o letra estándar.
- Eliminando las Stop words. A veces, algunas palabras extremadamente comunes que parecen tener poco valor para ayudar a seleccionar documentos que coinciden con las necesidades de un usuario se excluyen por completo del vocabulario. Estas palabras se llaman Stop words.
- Generación de derivaciones: derivación es el proceso de reducir las palabras con inflexión (o algunas veces derivadas) a su forma de raíz, base o raíz, generalmente una forma de palabra escrita. Ejemplo si tuviéramos que detener las siguientes palabras: “Pan” “panadero, “y panaderia”, el resultado sería una sola palabra “pan”.
- Lemmatización: una ligera variante de la derivación es la lematización. La principal diferencia entre estos es que, la derivación a menudo puede crear palabras inexistentes, mientras que los lemas son palabras reales. Por lo tanto, su raíz, es decir, la palabra con la que termina, no es algo que pueda buscar en un diccionario, pero sí puede buscar un lema. Algunos ejemplos de Lemmatización son que “correr” es una forma básica de palabras como “ccorriendo” o “corrió” o que la palabra “mejor” y “bueno” están en el mismo lema, por lo que se consideran iguales.
Bag of Words
Después de la fase de preprocesamiento inicial, necesitamos transformar el texto en un vector significativo (o matriz) de números. La bolsa de palabras es una representación de texto que describe la aparición de palabras dentro de un documento. Se trata de dos cosas:
• Un vocabulario de palabras conocidas.
• Una medida de la presencia de palabras conocidas.
¿Por qué se llama una “bag” of words? Esto se debe a que cualquier información sobre el orden o la estructura de las palabras en el documento se descarta y al modelo solo le preocupa si las palabras conocidas aparecen en el documento, no donde aparecen en el documento.
La intuición detrás de esta Bolsa de palabras es que los documentos son similares si tienen un contenido similar. Además, podemos aprender algo sobre el significado del documento solo a partir de su contenido.
Por ejemplo, si nuestro diccionario contiene las palabras {Learning, is, the, not, great}, y queremos vectorizar el texto “Learning is great”, tendríamos el siguiente vector: (1, 1, 0, 0, 1).
Enfoque TF-IDF
Un problema con el enfoque de la Bolsa de Palabras es que las palabras muy frecuentes comienzan a dominar en el documento (por ejemplo, mayor puntuación), pero es posible que no contengan tanto “contenido informativo”. Además, dará más peso a los documentos más largos que a los más cortos.
Un enfoque es volver a escalar la frecuencia de las palabras según la frecuencia con la que aparecen en todos los documentos, de manera que se penalicen las puntuaciones de las palabras frecuentes como “the” que también son frecuentes en todos los documentos. Este enfoque de puntuación se denomina Frecuencia de documentos de frecuencia inversa a término , o TF-IDF para abreviar, donde:
Frecuencia de término : es una puntuación de la frecuencia de la palabra en el documento actual.
TF = (Number of times term t appears in a document)/(Number of terms in the document)Frecuencia de documentos inversa : es una puntuación de cuán rara es la palabra entre los documentos.
IDF = 1+log(N/n), where, N is the number of documents and n is the number of documents a term t has appeared in.El peso de Tf-idf es un peso que se usa a menudo en la recuperación de información y la minería de texto. Este peso es una medida estadística que se utiliza para evaluar la importancia de una palabra para un documento de una colección o un corpus.
Ejemplo:
Considera un documento que contiene 100 palabras en donde la palabra “teléfono” aparece 5 veces.
El término frecuencia (es decir, tf) para teléfono es entonces (5/100) = 0.05. Ahora, supongamos que tenemos 10 millones de documentos y la palabra teléfono aparece en mil de estos. Luego, la frecuencia del documento inverso (es decir, IDF) se calcula como log (10,000,000 / 1,000) = 4. Por lo tanto, el peso de Tf-IDF es el producto de estas cantidades: 0.05 * 4 = 0.20.
Tf-IDF puede implementarse en scikit learn como:
desde sklearn.feature_extraction.text import TfidfVectorizer
Similitud coseno
TF-IDF es una transformación aplicada a los textos para obtener dos vectores de valor real en el espacio vectorial. Luego podemos obtener la similitud de coseno de cualquier par de vectores tomando su producto puntual y dividiéndolo por el producto de sus normas. Eso produce el coseno del ángulo entre los vectores. La similitud de coseno es una medida de similitud entre dos vectores distintos de cero. Usando esta fórmula podemos descubrir la similitud entre dos documentos d1 y d2.
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||Donde d1, d2 son dos vectores que no son cero.
Para una explicación detallada y un ejemplo práctico de TF-IDF y Cosine Similarity, consulta el documento a continuación.
Ahora tenemos una idea clara del proceso de la PNL. Es hora de que lleguemos a nuestra tarea real, es decir, la creación de nuestro chatbot. Llamaremos a nuestro chatbot ‘ROBO🤖’.
Importando las librerías necesarias.
import nltk
import numpy as np
import random
import string # to process standard python stringsCuerpo
Para nuestro ejemplo, usaremos la página de Wikipedia para chatbots como nuestro corpus. Copia el contenido de la página y colócalo en un archivo de texto llamado ‘chatbot.txt’. Si lo prefieres, puedes utilizar otro corpus.
Leyendo en los datos
Leeremos en el archivo corpus.txt y convertiremos el corpus completo en una lista de oraciones y una lista de palabras para un procesamiento previo adicional.
f=open('chatbot.txt','r',errors = 'ignore')raw=f.read()raw=raw.lower()# converts to lowercasenltk.download('punkt') # first-time use only
nltk.download('wordnet') # first-time use onlysent_tokens = nltk.sent_tokenize(raw)# converts to list of sentences
word_tokens = nltk.word_tokenize(raw)# converts to list of words
Veamos un ejemplo de sent_tokens y word_tokens
sent_tokens[:2]
['a chatbot (also known as a talkbot, chatterbot, bot, im bot, interactive agent, or artificial conversational entity) is a computer program or an artificial intelligence which conducts a conversation via auditory or textual methods.',
'such programs are often designed to convincingly simulate how a human would behave as a conversational partner, thereby passing the turing test.']word_tokens[:2]
['a', 'chatbot', '(', 'also', 'known']
Pre-procesamiento del texto crudo
Ahora definiremos una función llamada LemTokens que tomará como entrada los tokens y devolverá tokens normalizados.
lemmer = nltk.stem.WordNetLemmatizer()
#WordNet is a semantically-oriented dictionary of English included in NLTK.def LemTokens(tokens):
return [lemmer.lemmatize(token) for token in tokens]
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
Coincidencia de palabras clave
A continuación, definiremos una función para un saludo a través el bot, es decir, si la entrada de un usuario es un saludo, el bot devolverá una respuesta de saludo. ELIZA usa una palabra clave simple que coincide con los saludos. Utilizaremos el mismo concepto aquí.
GREETING_INPUTS = ("hello", "hi", "greetings", "sup", "what's up","hey",)GREETING_RESPONSES = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"]def greeting(sentence):
for word in sentence.split():
if word.lower() in GREETING_INPUTS:
return random.choice(GREETING_RESPONSES)
Generando respuesta
Para generar una respuesta de nuestro bot para preguntas de entrada, se utilizará el concepto de similitud de documentos. Entonces comenzamos importando los módulos necesarios.
- Desde la biblioteca scikit learn, importa el vectorizador TFidf para convertir una colección de documentos en bruto en una matriz de características TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer- Además, importa el módulo de similitud de coseno desde la biblioteca de aprendizaje de scikit
from sklearn.metrics.pairwise import cosine_similarityEsto se usará para encontrar la similitud entre las palabras ingresadas por el usuario y las palabras en el corpus. Esta es la implementación más simple posible de un chatbot.
Definimos una respuesta de función que busca la expresión del usuario para una o más palabras clave conocidas y devuelve una de las varias repsuestas posibles. Si no encuentra la entrada que coincide con ninguna de las palabras clave, devuelve una respuesta: “¡Lo siento! No te entiendo.
def response(user_response):
robo_response=''
sent_tokens.append(user_response)TfidfVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english')
tfidf = TfidfVec.fit_transform(sent_tokens)
vals = cosine_similarity(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2]if(req_tfidf==0):
robo_response=robo_response+"I am sorry! I don't understand you"
return robo_response
else:
robo_response = robo_response+sent_tokens[idx]
return robo_response
Finalmente, alimentaremos las líneas que queremos que diga nuestro robot al iniciar y finalizar una conversación, según la información del usuario.
flag=True
print("ROBO: My name is Robo. I will answer your queries about Chatbots. If you want to exit, type Bye!")while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response!='bye'):
if(user_response=='thanks' or user_response=='thank you' ):
flag=False
print("ROBO: You are welcome..")
else:
if(greeting(user_response)!=None):
print("ROBO: "+greeting(user_response))
else:
print("ROBO: ",end="")
print(response(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("ROBO: Bye! take care..")
Y eso es todo. Tenemos el codificado de nuestro primer chatbot en NLTK. Puedes encontrar el código completo con el corpus aquí . Ahora, veamos cómo interactúa con los humanos:

Esto no fue tan malo como parece. Incluso aunque el chatbot no pudo dar una respuesta satisfactoria a algunas preguntas, hizo un trabajo excelente en otras.
Conclusión
Aunque es un bot muy simple con casi ninguna habilidad cognitiva, es una buena manera de entrar en la PNL y aprender sobre los chatbots. Aunque ‘ROBO’ responde a las sugerencias del usuario. No engañará a sus amigos y, para un sistema de producción, querrá considerar una de las plataformas o marcos de bots existentes, pero este ejemplo lo ayudará a pensar en el diseño y el desafío de crear un chatbot. Internet está inundado de recursos. y después de leer este artículo, estoy seguro de que desearás crear un chatbot propio.
Espero que hayas encontrado útil este artículo. Déjame saber si tienes alguna duda o sugerencia en la sección de comentarios que verás a continuación.



